
Commercial content strategy at the enterprise level has officially moved past the era of novelty drafting. For professional copy editors, veteran content strategists, and computational linguists managing high-volume production pipelines, generative models are no longer toys—they are infrastructure. The deployment of the Anthropic Claude 4 generation—specifically the flagship Claude Opus 4.8 and the workhorse Claude Sonnet 4.6—has initiated a direct competition with OpenAI’s flagship lineup, including GPT-5.5, GPT-5.4, and the logic-optimized o-series.
When doing a comprehensive Claude 4 review, we have to move past marketing claims and analyze real-world text generation across long-form narrative coherence, style-guide compliance, surgical editing, and pipeline economics. This review assesses whether Anthropic’s current architecture genuinely outperforms OpenAI for professional writing, or if ChatGPT retains the operational edge.
Technical Performance Matrix: Claude 4 vs ChatGPT & Reasoning Models
To understand the core performance differences when weighing Claude 4 vs ChatGPT for content production, let’s break down the underlying operational metrics and financial models.
Model Cost, Context, and Architectural Profiles
| Model Tiers | Base Input Cost (per 1M) | Base Output Cost (per 1M) | Cached Input Cost (per 1M) | Context Window | Best Use Case Profile |
| Claude Opus 4.8 | $5.00 | $25.00 | $0.50 | 1,000,000 | Complex long-form, multi-step orchestration, legal drafts |
| Claude Sonnet 4.6 | $3.00 | $15.00 | $0.30 | 1,000,000 | Day-to-day writing, editing, high-volume content |
| Claude Haiku 4.5 | $1.00 | $5.00 | $0.10 | 200,000 | Low-latency chat, classification, light metadata |
| OpenAI GPT-5.5 | $5.00 | $30.00 | $0.50 | 1,050,000 | Multi-tool orchestration, multimodal generation |
| OpenAI GPT-5.4 | $2.50 | $15.00 | $0.25 | 1,000,000 | Production general-purpose, structured output |
| OpenAI o4-mini | $1.10 | $4.40 | $0.275 | 200,000 | Technical/logic-heavy drafting, budget reasoning |
1. Long-Form Prose and Narrative Coherence
Sustaining narrative momentum, structural flow, and thematic continuity over drafts exceeding 3,000 words reveals deep differences in how models manage their attention mechanisms. Autoregressive language models historically suffer from the “lost-in-the-middle” phenomenon, where the middle portion of a long context window experiences degraded recall and structural drift.
Claude Opus 4.8 exhibits a measurable advancement in context processing, demonstrating a GraphWalks Long-Context F1 score of 68.1% over a one-million-token span—a substantial improvement from the 40.3% recorded by Opus 4.7. In practice, this architectural capability allows long documents to maintain structural integrity, ensuring that stylistic constraints, character arcs, or technical parameters introduced in the initial paragraphs do not dissolve as the output approaches the model’s 128,000-token maximum output limit.
A primary differentiator when evaluating Claude 4 vs ChatGPT is the presence of a distinct “AI accent”. Standard ChatGPT outputs, particularly from the GPT-4o and GPT-5.4 families, often display high predictability in word selection, a consequence of low semantic perplexity. Perplexity measures the probability distribution of subsequent tokens:
$$\text{PP}(W) = P(w_1, w_2, \dots, w_N)^{-\frac{1}{N}}$$
When a model optimizes for low perplexity, it defaults to the most predictable token sequences. This manifests as a uniform, sanitized corporate register characterized by repetitive transitional phrases (such as “delve,” “testament,” “pave the way,” and “furthermore”) and a structural reliance on parallel, three-item bulleted lists poorly disguised as prose paragraphs.
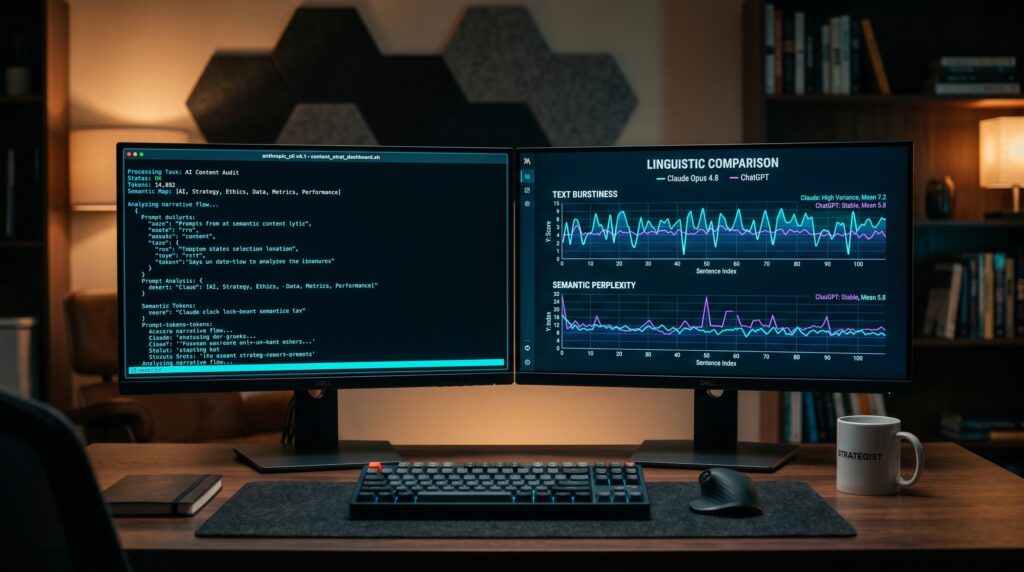
To quantify this structural predictability, computational linguists measure text burstiness, which evaluates the standard deviation of sentence lengths across a document. The burstiness coefficient is formulated as:
$$\text{Burstiness} = \frac{\sigma_{L}}{\mu_{L}}$$
Where $\sigma_{L}$ represents the standard deviation of sentence lengths (measured in word count per sentence) and $\mu_{L}$ represents the mean sentence length. Human-written prose naturally exhibits high burstiness ($\text{Burstiness} \ge 0.60$), combining short, declarative clauses with winding, compound-complex structures.
Standard ChatGPT outputs typically register a low-burstiness score between $0.18$ and $0.25$, reflecting highly uniform sentence lengths. Claude Sonnet 4.6, under standard settings, achieves a slightly higher baseline of $0.20$ to $0.30$.
However, Claude Opus 4.8 generates prose with varied sentence lengths and complex syntactic distributions that closely mirror human writing styles. This structural variety allows Claude’s output to bypass automated AI detectors more effectively than ChatGPT, as shown below:
[ChatGPT Generation] ──► Low Burstiness (0.15-0.25) ──► Uniform Staccato ──► High AI Detection
[Claude Opus 4.8] ──► High Burstiness (0.55-0.75) ──► Varied Prose ──► Low AI Detection
Writers must note that Claude Sonnet 4.6 exhibits specific prose vulnerabilities when operating under standard, low-effort configurations. To throttle compute usage, default API calls on Sonnet 4.6 often result in run-on sentences, comma splices, and a repetitive reliance on “-ing” modifier constructions (e.g., “, shifting the focus to…”) to attach secondary actions to independent clauses. This behavior can be mitigated by configuring explicit custom skills that split independent clauses, enforce a strict limit on sequential conjunctions, and require correct punctuation for dialogue and interrogative sentences.
2. Tone Control and Style-Guide Compliance
Enforcing compliance with complex corporate style guides is a critical test of a model’s semantic steering capabilities. Brands rarely communicate in binary registers; instead, they require subtle, blended tones such as “confident but not arrogant” or “authoritative but collaborative”.
OpenAI models trained primarily via standard Reinforcement Learning from Human Feedback (RLHF) tend to struggle with these nuanced boundaries. In attempting to maintain a helpful and engaging persona, ChatGPT often defaults to an overly enthusiastic, conversational tone that borders on sycophancy, or it homogenizes specific brand personalities into a standardized public relations register.
Conversely, Anthropic’s integration of Constitutional AI principles trains Claude models to adhere strictly to structural guidelines and ethical boundaries, which correlates with an innate capacity to respect complex, rule-based styling constraints. When presented with a multi-layered brand personality matrix, Claude Opus 4.8 maps the semantic space of tone attributes by systematically evaluating what a trait represents in practice versus its negative manifestation (e.g., ensuring “boldness” does not drift into “combative” rhetoric).
The models also diverge in how they process few-shot example-based voice training. OpenAI’s persistent memory systems and Custom GPT configurations rely on generalized vector recall, which is subject to context dilution and style drift over extended, multi-turn dialogues. This limits their ability to sustain hyper-specific formatting exceptions across a long session.
Claude addresses this by utilizing native feature architectures such as Projects and custom markdown schemas, including .claude/product-marketing-context.md or SKILL.md brand-voice protocols. This allows the AI coding agent platform to load, parse, and enforce localized style sheets directly within the session context. By defining clear “Tone Situations” (e.g., shifting the emotional inflection from a celebratory tone in a product launch to a transparent, empathetic register during service outages), Claude maintains style-guide compliance across diverse channels.
3. Editing and Structural Rewriting
An experienced copy editor requires a model to act as a surgical instrument, executing precise structural adjustments, tightening syntax, and pruning hedge phrases without erasing the unique voice of the original author. When executing rewriting tasks, ChatGPT displays a homogenization bias, often rewriting the input text from scratch to conform to a standard corporate template. This “all-or-nothing” approach strips the prose of its natural human cadences, replacing varied vocabulary with generic, highly predictable synonyms.
In contrast, the Claude 4 family excels at targeted, non-destructive editing. The highlight-to-edit workflow—where specific sections are isolated for adjustment—is highly efficient with Sonnet 4.6, allowing content teams to tighten weak arguments or adjust readability levels for specific target audiences without burning the premium API credits required by Opus-tier models.
This surgical precision is controlled by the “effort” parameter, which dictates the amount of computational resources allocated to pre-output reflection. On Claude Opus 4.8, this parameter defaults to “high” across all APIs and developer tools, ensuring that the model conducts deep, multi-step critical evaluations of prose structure before generating output.
This deliberative processing manifests in a 0% rate of uncritically reporting flawed analytical results and a ten-fold reduction in overconfidence compared to prior generations. Consequently, Opus 4.8 acts as a highly reliable developmental editor, identifying logical contradictions or stylistic inconsistencies with clinical accuracy.
Meanwhile, OpenAI’s reasoning-focused o-series models (such as o1 and o3) allocate substantial inference-time computation to mathematical and programmatic verification. While these reasoning chains are highly effective for algorithmic coding or scientific translation, they introduce significant latency and high token costs to standard editorial workflows without delivering a proportional improvement in stylistic or creative output.
4. Creative Originality vs. SEO Production
For enterprise content pipelines, scaling production requires balancing semantic originality with the operational realities of API costs. High semantic originality relies on a model’s ability to avoid obvious token-level predictions, selecting synonyms and conceptual associations that display high lexical diversity and high perplexity.
While ChatGPT remains highly optimized for rapid, high-volume transactional copy—such as standard SEO descriptions or basic product landing pages—its outputs are highly vulnerable to automated AI detection mechanisms because of their low perplexity and predictable token distributions. Claude Opus 4.8 displays a broader semantic range, making it highly effective for thought leadership essays, detailed strategy documents, and original marketing copy.
Prompt caching is the primary operational lever for reducing costs on repetitive context blocks. Anthropic and OpenAI implement different technical mechanisms for cache management. Anthropic uses explicit cache_control breakpoints, requiring content engineers to flag the end of stable system prompts or style guides in code. While cache writes incur a 1.25× premium ($6.25/M on Opus 4.8), cached input reads are billed at a 90% discount ($0.50/M). OpenAI’s caching is automatic for any prompt prefix exceeding 1,024 tokens and applies a similar 90% discount on cached reads for its GPT-5.4 and GPT-5.5 flagships.
To maximize these economics in editorial pipelines, developers must structure their requests using a strict “stable-to-variable” hierarchy. Any change in the initial tokens of a prompt invalidates the entire subsequent Key-Value (KV) cache.
Plaintext
[STABLE PREFIX - CACHE TARGET]
1. Complete Brand Style Guidelines (~15,000 tokens)
2. Structural Output Templates (~5,000 tokens)
3. Custom Editing Rules (e.g., no comma splices) (~2,000 tokens)
--------------------- [CACHE BREAKPOINT] ---------------------
[VARIABLE SUFFIX - UNCACHED]
4. The specific source text to edit or prompt brief (~1,000 tokens)
By placing static assets (e.g., massive style guides, product databases, and few-shot examples) at the beginning of the prompt sequence, enterprise pipelines can run multi-stage editing runs on Claude Sonnet 4.6, incurring only $0.30 per million input tokens for subsequent reads rather than the full $3.00 standard rate.
AI Review Zones Verdict & Strategic Recommendations
The choice between Claude 4 and ChatGPT for professional writing is defined by the technical demands of the content pipeline rather than a single superior metric.
At AI Review Zones, our operational verdict is clear: Claude Opus 4.8 is the absolute gold standard for high-value, long-form prose. It successfully breaks away from the predictable, staccato “AI accent” that continues to plague OpenAI’s models, generating human-like burstiness that reads naturally. For brand managers who need strict style-guide compliance and surgical, non-destructive editing, Anthropic’s flagship architecture completely outclasses the competition.
However, ChatGPT (specifically GPT-5.4) remains an elite, cost-effective engine for rapid, short-form transactional copy, high-volume SEO metadata, and generic drafting where syntactic variety is secondary to raw speed.
To maximize both output quality and budget efficiency, enterprise content pipelines should utilize a hybrid orchestration pattern. Under this framework, Claude Opus 4.8 acts as the central AI agent orchestrator—planning narrative structures, establishing stylistic frameworks, and performing final compliance audits—while delegating localized drafting, translation, and text expansion tasks to Sonnet 4.6 or GPT-5.4. This approach leverages the distinct strengths of both architectures to produce high-quality humanized prose while minimizing API expenditures.
🌐 Explore More from Our AI Production Series
- Autonomous Engineering Workspace Reviews: Read our hands-on OpenHands Review: A Brutally Honest Look at the Open-Source AI Software Engineer to see how a model-agnostic, fully sandboxed stack behaves in production workflows.
- Terminal-Native Power Tools: Dive into our recent Claude Code Review: A Blunt, Production-Tested Evaluation of Anthropic’s CLI Agent to master the safety guardrails and caching strategies required for agentic terminal loops.
- Deep Research Memory Frameworks: Check out our Mem0 vs Letta Architectural Comparison to select the ultimate long-term memory layer for your production agent network.
- Advanced Agent Orchestration: Read our deep LangGraph Review: A Production-Grade Evaluation of the Cyclical AI Agent Orchestrator to learn how to manage complex loops and avoid database checkpointer bottlenecks.